WebViewer Version:
Do you have an issue with a specific file(s)?
No
Can you reproduce using one of our samples or online demos?
No
Are you using the WebViewer server?
No
Does the issue only happen on certain browsers?
No
Is your issue related to a front-end framework?
No
Is your issue related to annotations?
Yes
Please give a brief summary of your issue:
I got wrong paragraphId and flowId based on this sample:
https://www.pdftron.com/documentation/samples/js/TextExtractTest (example4Advanced)
Please describe your issue and provide steps to reproduce it:
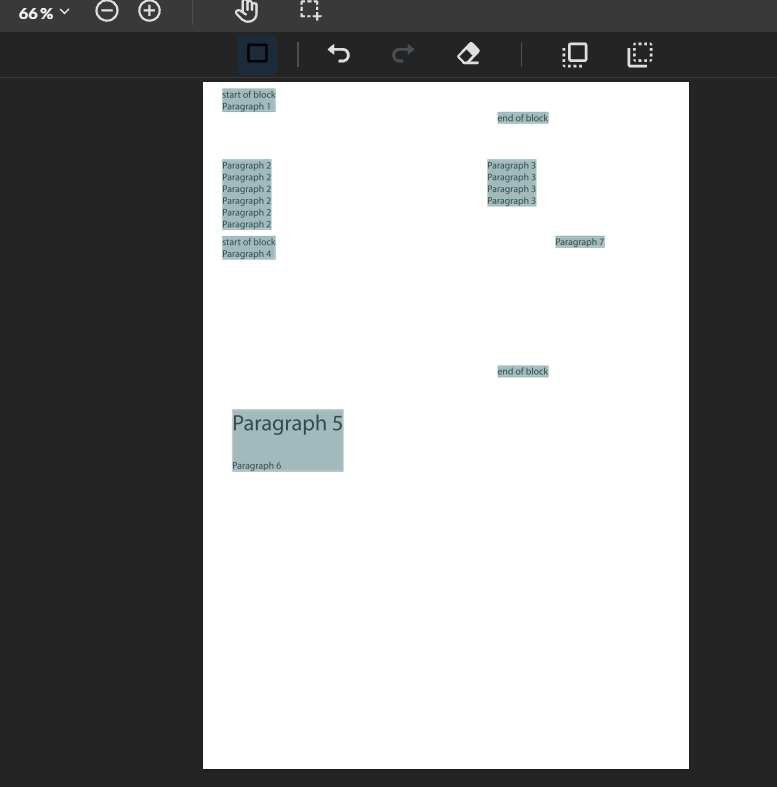
I’m uploading a text pdf to webviewer and I wonder to detect text paragraphs based on the sample above, that gives me paragraphId of each line from the pdf.
The code from the sample works well, but getting wrong flowId and paragraphId.
I’m testing with this file:
test from illustrator.pdf (797.3 KB)
In that file I have 7 different paragraphs, but with the sample code it detect 8 paragraphs, and some of those paragraphs are separated, like the ones that have break line inside the paragraph.
this is a picture from the wevViewer of what I got.
and finally this is a picture from illustrator where I create the PDF.


