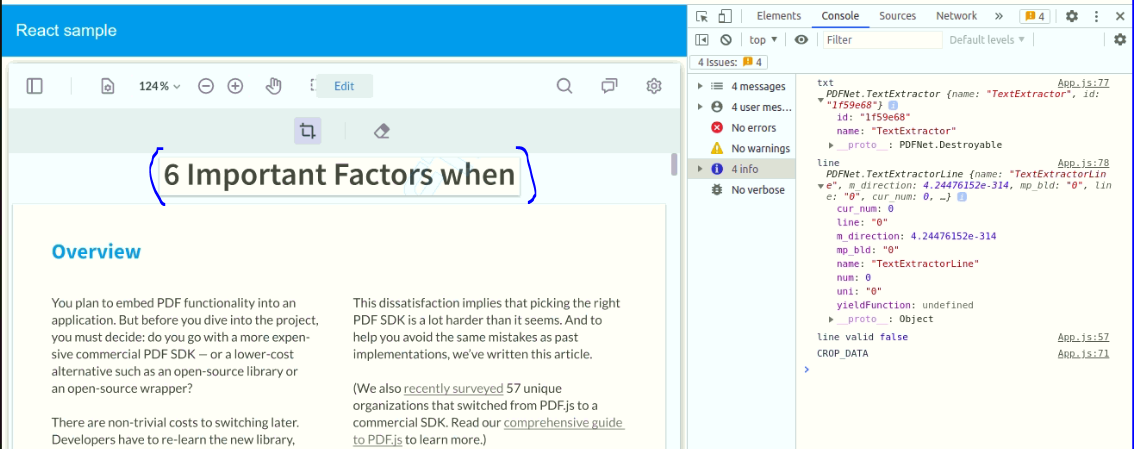
hi, I’m trying to extract the text from cropped dataURL but I’m facing the issue : Exception:
Message: PDF header not found. The file is not a valid PDF document.
Conditional expression: false
Version : 9.1.0-cd205f5552
Platform : Emscripten
Architecture : Emscripten
Filename : Parser.cpp
Function : SkipHeader
Linenumber : 1163
“”
import React, { useRef, useEffect, useState } from ‘react’;
import WebViewer from ‘@pdftron/webviewer’;
import ‘./App.css’;
const App = () => {
const viewer = useRef(null);
const [crop, setCrop] = useState(null);
useEffect(() => {
WebViewer({
path: ‘/webviewer/lib’,
initialDoc: ‘/files/PDFTRON_about.pdf’,
fullAPI: true,
},
viewer.current,
).then(instance => {
instance.UI.disableElements([‘toolbarGroup-Shapes’]);
instance.UI.disableElements([‘toolbarGroup-View’]);
instance.UI.disableElements([‘toolbarGroup-Annotate’]);
instance.UI.disableElements([‘toolbarGroup-FillAndSign’]);
instance.UI.disableElements([‘toolbarGroup-Forms’]);
instance.UI.disableElements([‘toolbarGroup-Insert’]);
// const { docViewer, annotManager } = instance;
const { documentViewer, annotationManager, Tools, PDFNet } = instance.Core;
instance.setToolMode('CropPage');
instance.disableElements(['redoButton', 'undoButton']);
var FitMode = instance.FitMode;
instance.setFitMode(FitMode.FitWidth);
const applyCrop = Tools.CropCreateTool.prototype.applyCrop;
Tools.CropCreateTool.prototype.applyCrop = function (e) {
const filename = documentViewer.getDocument().getFilename();
const doc = PDFNet.PDFDoc.createFromURL(filename); // issue is there
const annotation = annotationManager.getAnnotationsList().find(annotation => annotation.ToolName === "CropPage")
const cropRect = annotation.getRect();
documentViewer.getDocument().loadCanvasAsync({
pageNumber: annotation.PageNumber,
renderRect: cropRect,
drawComplete: async (canvas, index) => {
console.log('CROP_DATA', canvas.toDataURL());
}
});
applyCrop.apply(this, arguments);
};
}).catch((error) => {
console.log('error', error);
});
}, []);
return (
);
};
export default App;