Do you have an issue with a specific file(s)? No
Can you reproduce using one of our samples or online demos? Yes
Are you using the WebViewer server? Yes (assuming the demo is using it)
Does the issue only happen on certain browsers? No
Is your issue related to a front-end framework? No
Is your issue related to annotations? No
Please give a brief summary of your issue:
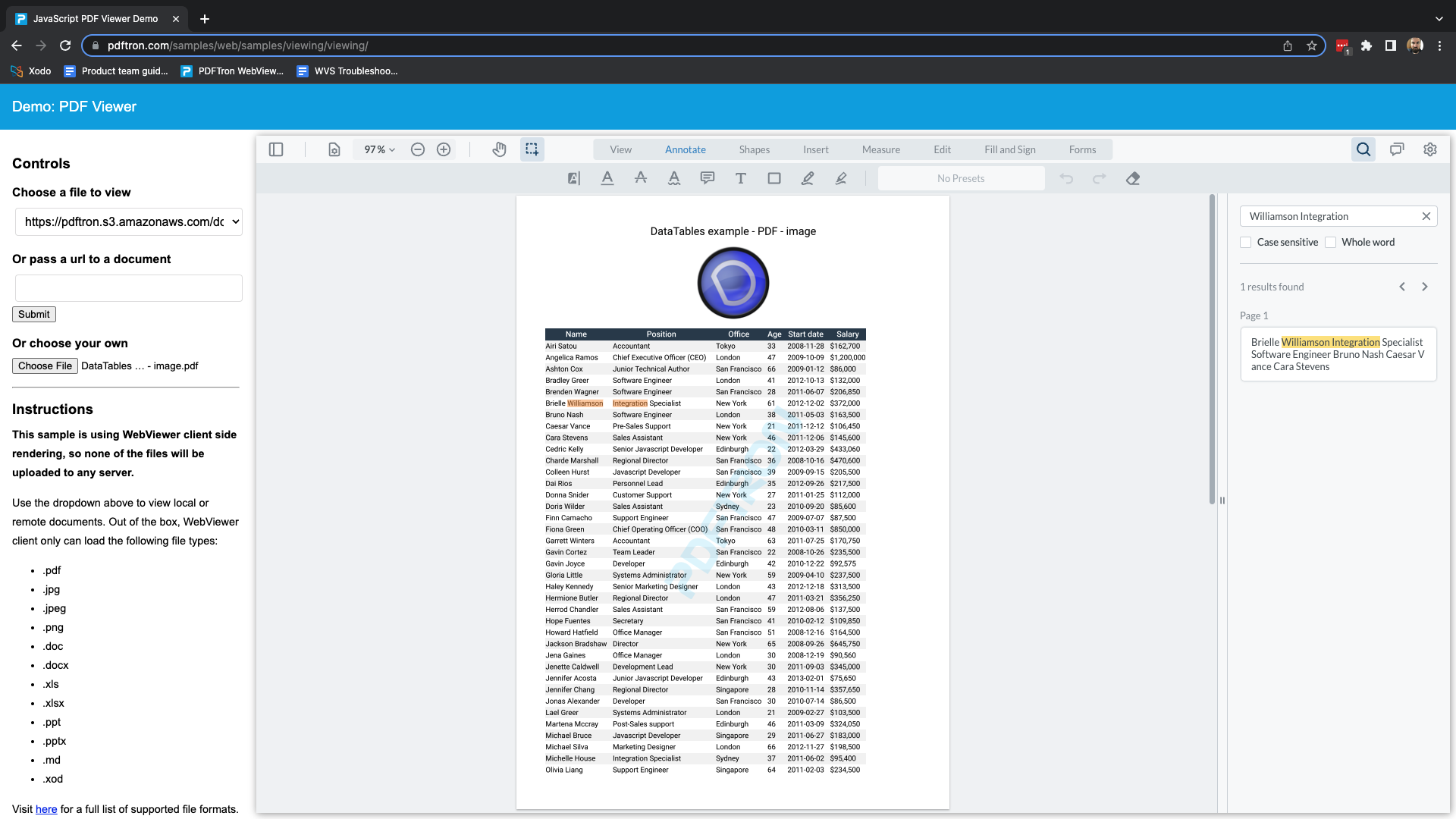
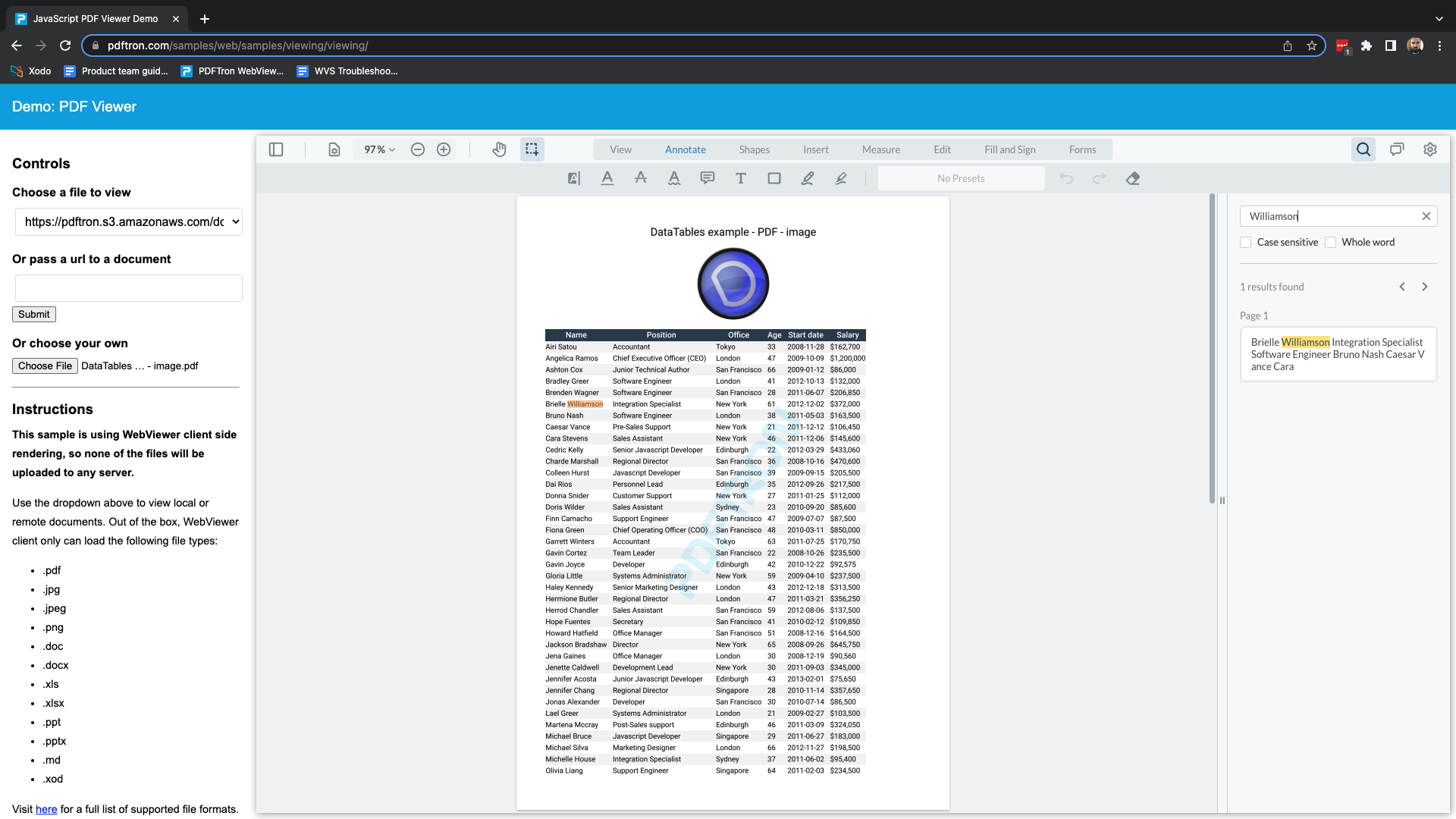
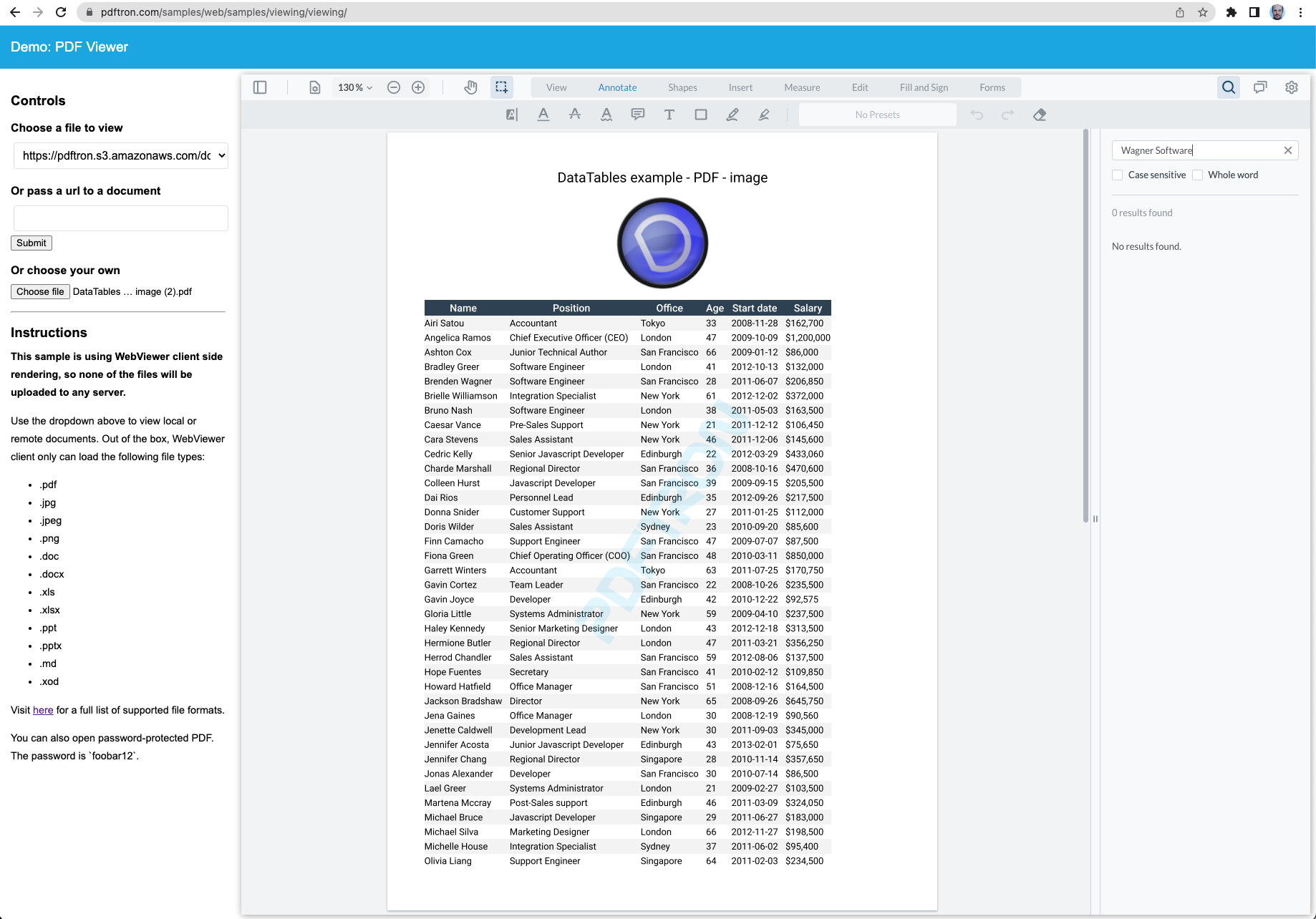
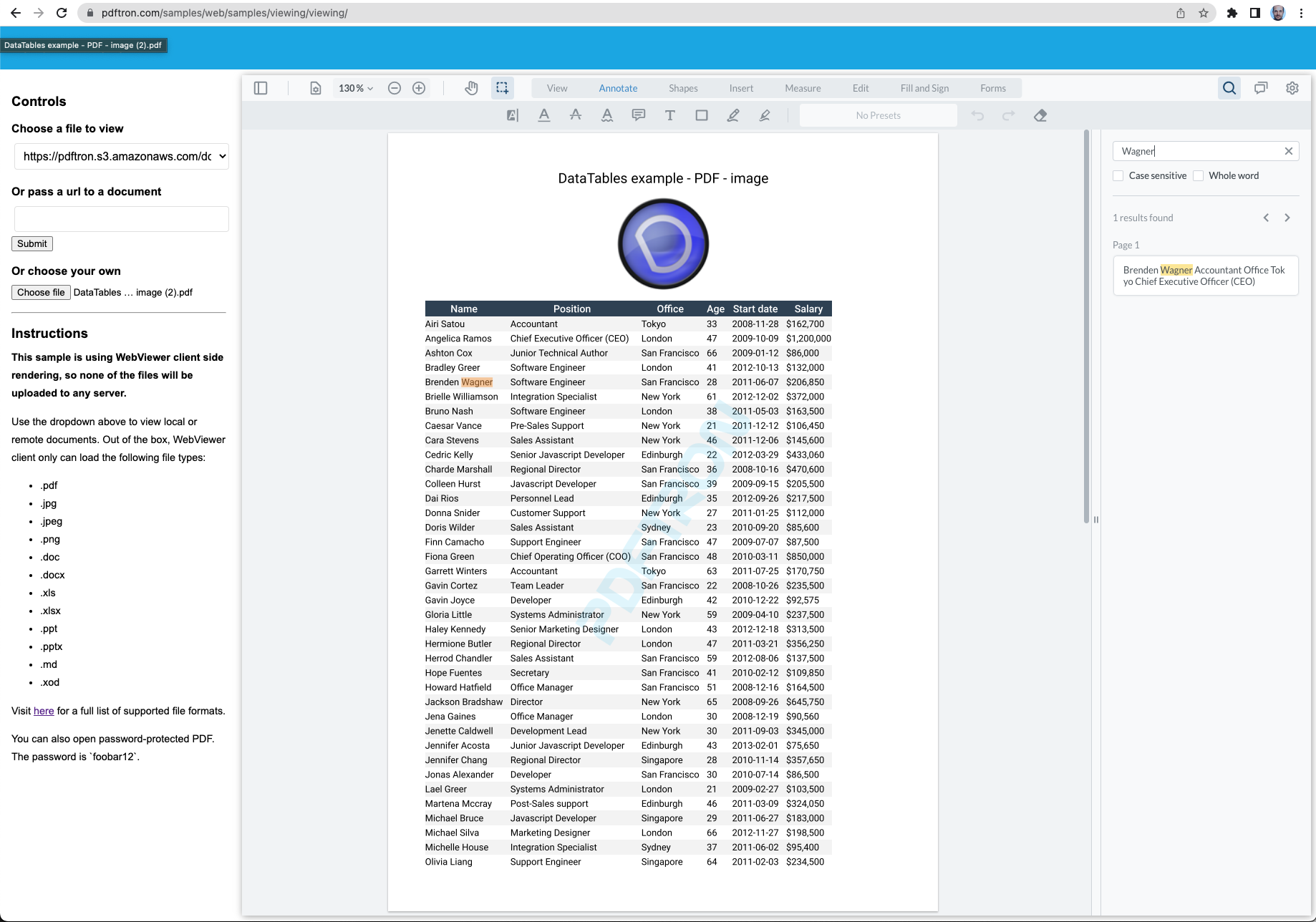
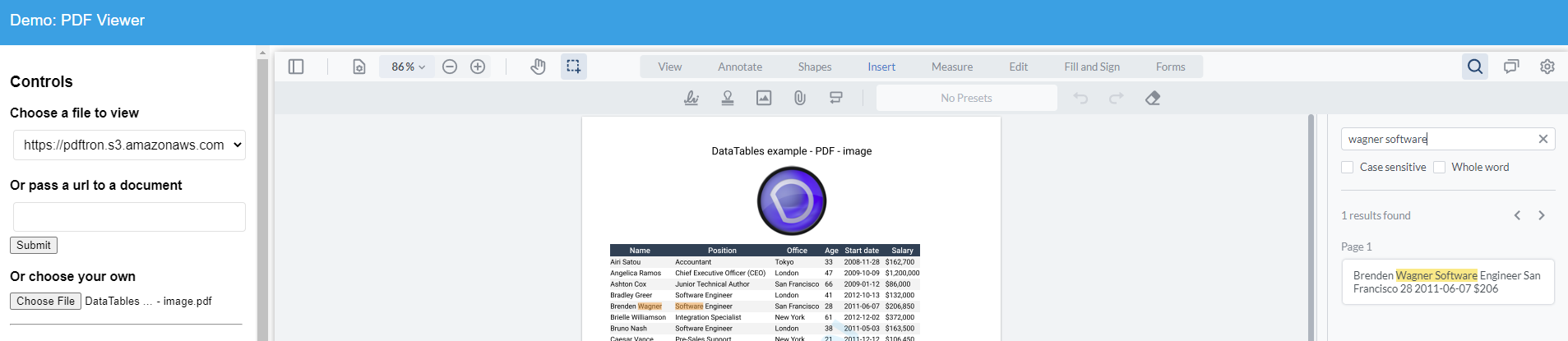
Searching content in a table inside a PDF is hardly usable, because the text is not parsed in the same way it is displayed (jumping around, instead of row by row)
Please describe your issue and provide steps to reproduce it:
Latest official builds, and Release channel, are ready for production usage, however the developer channel builds do not get the same amount of testing and can be in a state of change.
And then add the following code to use an alternate means of extracting/parsing text from a PDF.
I finally got around to testing your suggestion. Instead of the nightly build, I used the 8.7.0 release version.
Unfortunately, it seems that this setting has no impact on the problem at hand.
The search results are appearing in the exact same order for me.
Is there any way to verify if the flag has been activated properly? Do you maybe have a test case I can try to make sure that I got it implemented correctly?
Thanks @Ryan for the full example! I can indeed verify your code.
However, replacing the library in your example with the release version of 8.7.0, it no longer works…
I tried both installing via npm and downloading the SDK.
Did this feature maybe not make it to the release?
Strangely, I’m not getting any typescript linter issues – EXTRACT_USING_ZORDER is properly defined.
Which build of WebViewer are you using (can I get a link to it)? I tested the latest nightly and 8.7 build on npm and both seems to be working with the “EXTRACT_USING_ZORDER” option
^when using npm, make sure the public static folder WebViewer is pointing to is up to date
Searching with EXTRACT_USING_ZORDER enable wasn’t working in the official 8.7 release but has been fixed in the nightly builds. It should also be in the upcoming 8.8 release which should come out in the next few weeks. It could be possible that your browser is caching an older version of WebViewer without the fix
Thank you for the update and I’m glad that worked for you. We are in the middle of testing and bug fixing for our next 8.8 release currently. Hopefully, it should be released by the end of next week but we could find something that could delay the release.