Product: Webviewer
Product Version: 7.3.0
Please give a brief summary of your issue:
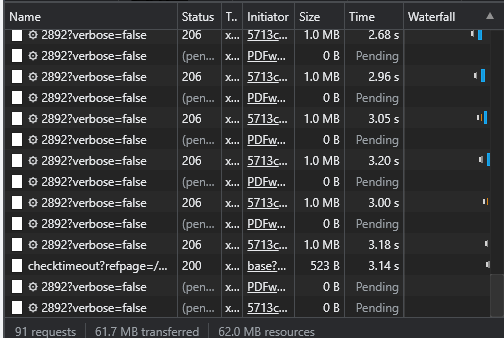
I am having issues with regards to the performance of pdftron viewer. Specifically when navigating through a pdf file with many pages, I try to navigate to an arbitrary page in the middle of the file and wait for the page to load, But it takes more than a minute to show up.
In the video above, I am first supplying an api endpoint to provide the pdf to be loaded. in the 2nd half of the video, I am using a direct link to a pdf file in the server. As you can see, supplying the direct pdf file is faster to load.
Here is the endpoint in question
[Authorize]
public async Task<ActionResult> AttachmentPartial(int id, bool? verbose = true)
{
var pathSession = this.Session[$"AttachmentPath{id}"];
var fileNameSession = this.Session[$"AttachmentPathFileName{id}"];
var fileContentSession = this.Session[$"AttachmentPathContent{id}"];
var path = string.Empty;
var fileName = string.Empty;
byte[] fileContent = null;
DateTime dateModified;
var mimeType = string.Empty;
if (pathSession != null)
path = pathSession.ToString();
if (fileNameSession != null)
fileName = fileNameSession.ToString();
if (fileContentSession != null)
fileContent = (byte[])fileContentSession;
var willLog = false;
if (verbose.HasValue)
willLog = verbose.Value;
if (pathSession != null && fileNameSession != null && willLog)
AuditLog.Log(false, $"Cache for AttachmentPartial is hit: (AttachmentPath{id})", Shell.User, this.PageCode, EventType.Info, this.PageCode);
if (string.IsNullOrEmpty(path) || string.IsNullOrEmpty(fileName) || fileContent == null)
{
path = GetAttachment(id, verbose ?? true, out fileName);
this.Session[$"AttachmentPath{id}"] = path;
this.Session[$"AttachmentPathFileName{id}"] = fileName;
if (!System.IO.File.Exists(path))
return Redirect(WebHelper.ContentUrl("Error/FileNotFound"));
fileContent = await Task.Run(() =>
{
var file = System.IO.File.ReadAllBytes(path);
this.Session[$"AttachmentPathContent{id}"] = file;
return file;
});
}
if (!System.IO.File.Exists(path))
return Redirect(WebHelper.ContentUrl("Error/FileNotFound"));
dateModified = System.IO.File.GetLastWriteTime(path);
mimeType = MimeMapping.GetMimeMapping(path);
return new RangeFileContentResult(fileContent, mimeType, fileName.Replace("%", "% "), dateModified);
}
In the above code, basically read the contents of the file and output the byte range based on what the webviewer requests.
Subsequent requests doesn’t access the database because the data is already stored in session.
What I am asking is how can I improve the performance of my api endpoint? Is there any other configuration I can toggle to improve the webviewer’s performance?
Some additional information:
1.) The pdf file(s) are linearized.
2.) SharedArrayBuffer is enabled
3.) Byte Range Requests are enable
I can provide access to the site in question via email or any other private way.