Exception:
Message: An error occurred while converting the file.
Detailed error:
Error converting text content using Text2PDF module.
Conditional expression: false
Filename : Convert.cpp
Function : trn::PDF::Convert::ToPdf
Linenumber : 1605
when execute
pdftron.PDF.Convert.ToXod(filename, outputPath_xod);
OR
pdftron.PDF.Convert.ToPdf(pdfdoc, filename);
BTW
Hebrew chars inside doc(x) to pdf/xod conversion works nicely!
sure
all those text files includes hebrew chars
even if one char is in hebrew (in mixed english / heb content)
the internal pdftron txt parser will complain:)
It turns out that the encoding for these files are Hebrew - Windows 1255 which we currently don’t support unfortunately. That’s why PDFNet complains because in our old sdk, only UTF encoding is accepted when converting text to pdf.
If you can try our latest nightly builds with utf-encoded files, the problem should be resolved. I have attached a utf-8 version of one of the attachments you sent in this email. Feel free to give it a try using our latest nightly builds.
Please let me know if this works for you, and if you have any further questions.
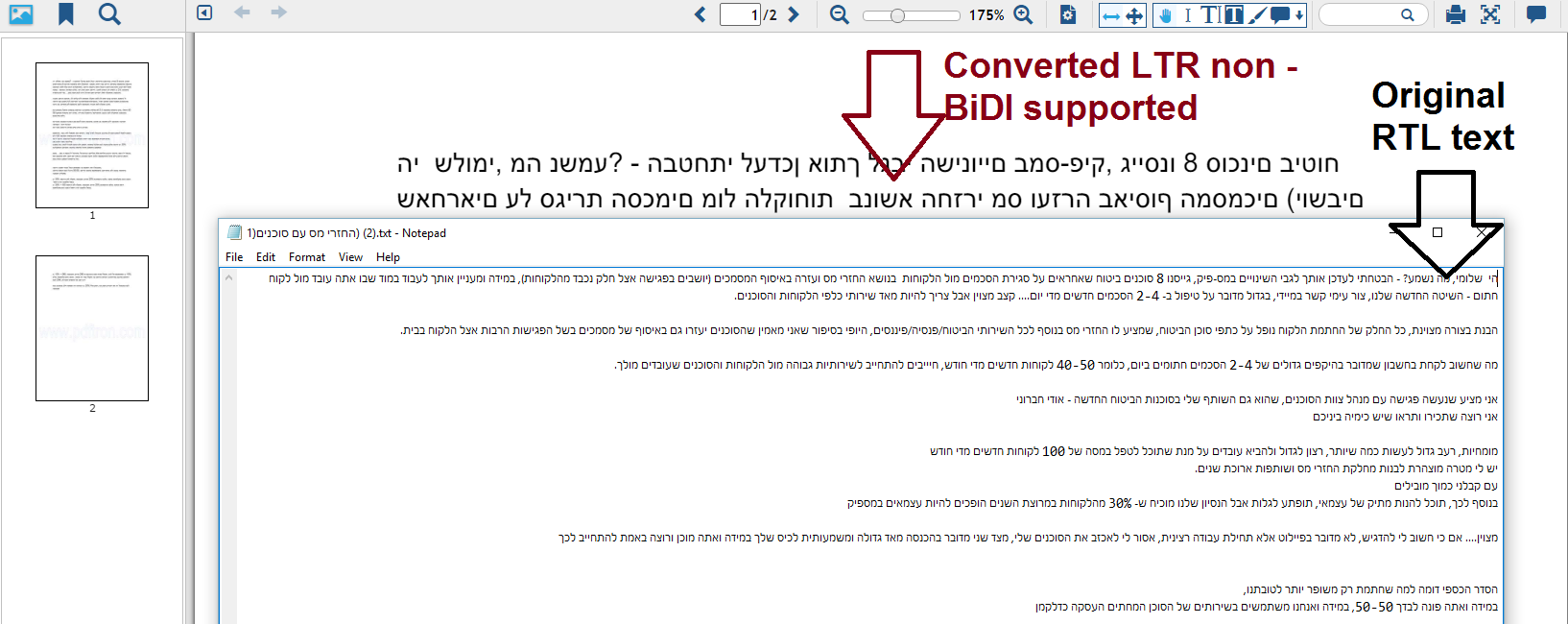
i tried your latest experimental - PDFNetDotNet4_2016-08-18_stable_rev47484.zip
it has been manage to show hebrew chars, but not as normal RTL - Bi-Directional
but as Jebreish (LTR words - unreadable)
attached a compare of ur original heb utf vs your converted result with latest nightly build