Please give a brief summary of your issue: PDFTron SDK not able to find OCR module
Please describe your issue and provide steps to reproduce it:
So I am using PDFTron SDK in my Node.js app in a linux environment (Pop OS 22.04). I am facing a problem that the SDK is not able to find the OCR module.
I even downloaded the module and extracted the zip file, put it in a lib folder and passed the path of that folder to this function PDFNet.addResourceSearchPath('path to my lib folder') but that didn’t work. So I passed the path of the OCR module folder itself placed in my lib folder but again got the same error.
Error I got:
Unable to run OCRTest: PDFTron SDK OCR module not available.
The OCR module is an optional add-on, available for download
at http://www.pdftron.com/. If you have already downloaded this
module, ensure that the SDK is able to find the required files
using the PDFNet.addResourceSearchPath() function.
Here is the code where I used PDFNet.addResourceSearchPath() :
async function _extract(file) {
try {
await PDFNet.addResourceSearchPath('../../lib');
const useIRIS = await PDFNet.OCRModule.isIRISModuleAvailable();
if (!(await PDFNet.OCRModule.isModuleAvailable())) {
console.log('\nUnable to run OCRTest: PDFTron SDK OCR module not available.');
console.log('---------------------------------------------------------------');
console.log('The OCR module is an optional add-on, available for download');
console.log('at http://www.pdftron.com/. If you have already downloaded this');
console.log('module, ensure that the SDK is able to find the required files');
console.log('using the PDFNet.addResourceSearchPath() function.\n');
throw new ServiceError();
}
const doc = await PDFNet.PDFDoc.createFromBuffer(file.buffer);
await doc.initSecurityHandler();
const opts = new PDFNet.OCRModule.OCROptions();
setLanguage(useIRIS, opts);
await PDFNet.OCRModule.processPDF(doc, opts);
const buf = await doc.saveMemoryBuffer(
PDFNet.SDFDoc.SaveOptions.e_linearized
);
const buff = [];
buff.push(buf);
metadata.files.push({
originalName: file.originalname,
size: file.size,
compressedSize: Buffer.byteLength(buf),
});
metadata.buffer = [...metadata.buffer, ...buff];
} catch (err) {
throw new ServiceError(err);
}
}
I am confused and don’t have any clue about what to do next so can you guys help me out?
Please provide a link to a minimal sample where the issue is reproducible:
extracted the zip file
For Linux it would be a tar.gz file, perhaps this is the issue, as the zip file would be for Windows.
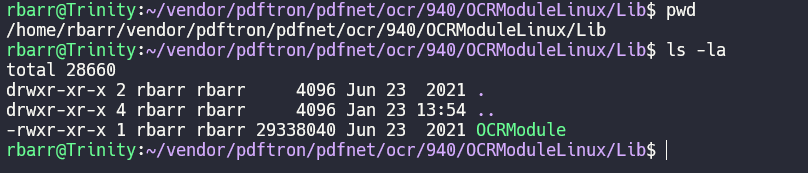
If you are using our regular OCR module, then if your code was the following. PDFNet.addResourceSearchPath("/home/rbarr/vendor/pdftron/pdfnet/ocr/940/OCRModuleLinux/Lib");
Then your folder of the above path would like the following.
Actually, I extracted the tar.gz file I am habitual to calling it as a zip file my bad but this path you mentioned "/home/rbarr/vendor/pdftron/pdfnet/ocr/940/OCRModuleLinux/Lib" I don’t have any such directories as I am using pdftron as a node package and all the other services which I intended to use are working just fine and as for setLanguage(useIRIS, opts); that function handles the if(useIRIS) opts.setOCREngine('iris');
But please help me with that path stuff I mentioned earlier, and an early reply will be appreciated!
How will I be able to deploy it? I have already downloaded the module and extracted it. The documentation & the links you have provided also don’t provide any information about doing the same. Early response will be appreciated!
Just copy over all the files for the OCR module, and make sure PDFNet.addResourceSearchPath is pointing to the folder where you copied the OCR module files to.
I did passed the path to the folder you can see in the code it’s the path to the lib folder and also to the OCR module folder after extraction but nothing happend in both the ways, I get the same error as earlier.
The PDFTron SDK OCR module not available. error means one thing, the expected OCR Module files are not in the folder path you provided to addResourceSearchPath, that’s what you need to resolve.
In your original message you gave a relative path, perhaps that relative path is not correct in your deployment, perhaps giving it an absolute path is better/safer.
You could either log the current working directory at runtime, to see if that matches what you expect, or better yet programmatically check at runtime that the OCR module is ../../lib folder.
I added the absolute path but now I am facing this error tho I have a demo license key but by following the link I am getting the same form that I already filled out to gain access to the demo key and use other services of Apryse formally Pdfrtron.
The connection to the server has timed out! This is likely due to your firewall or networking configuration. This delay can be avoided by obtaining and using a non-tracking key. You can obtain one by filling out https://www.pdftron.com/form/pws-non-tracking/.