i want to save a cropped data from PDF using pdftron. i’m using react framework
Hello, I’m Ron, an automated tech support bot 
While you wait for one of our customer support representatives to get back to you, please check out some of these documentation pages:
Guides:- Core engine for WebViewer - Creating your own UI using WebViewer Core
- Decrypt & read a PDF document using JavaScript - About reading a secured document
- PDFTron Custom Security Handler using JavaScript - Encrypting a PDFTron Custom secured document using the password and application custom id
- Lock a PDF document using JavaScript - About locking a document
1 Like
Hello there.
Could you elaborate more on what exactly you want to do? Some [visual] examples would really help.
Best Regards,
Diego Felix
Web Software Developer
PDFTron Systems, Inc.
www.pdftron.com
CONFIDENTIALITY NOTICE: This message (and any attachment to it) is intended only for the use of the individual or entity to which it is addressed in the header, and may contain information that is privileged, confidential and exempt from disclosure under applicable law. Any reproduction, distribution, modification or use of the contents of this message (and any attachment to it) by any individual or entity other than the intended recipient is prohibited. If you have received this communication in error, please notify us immediately and delete the original.
1 Like

I’m trying to get cropped portion of the page, in PDFTron by default it crops the page and creates a new page with the cropped part. I want to get the cropped part of the page in form of an blob data or base64
1 Like
Hello there.
Thanks for the additional info.
Here is a code snippet that might help:
WebViewer({ }, document.getElementById('viewer')
).then(instance => {
const { docViewer, annotManager } = instance;
// this example is using the 'Crop' tool, you can use other tools if you want
instance.setToolMode('CropPage');
// when a new crop area is adeded
annotManager.on('annotationChanged', async function(annotationData, action, { imported }) {
if (action === 'add'
&& annotationData[0]
&& annotationData[0].ToolName === "CropPage") {
// get the positions of the crop that was added to extract information from
const cropRect = annotationData[0].getRect();
docViewer.getDocument().loadCanvasAsync({
pageNumber : annotationData[0].PageNumber,
renderRect: cropRect,
drawComplete: async (canvas, index) => {
// The 'canvas' would be the cropped area of the page.
// You can use 'toBlob' or 'toDataURl' extra the data from the canvas
}
});
}
});
});
Best Regards,
Diego Felix
Web Software Developer
PDFTron Systems, Inc.
www.pdftron.com
Hi ,
thanks for your support, is there any possible to get a canvas data after we clicked the crop (tick) button

Hello there.
Yes, it’s possible if you override the applyCrop function from the crop tool. Here is how you do it:
Webviewer(...).then(async (instance) => {
const { documentViewer, annotationManager, Tools } = instance.Core;
const applyCrop = Tools.CropCreateTool.prototype.applyCrop;
Tools.CropCreateTool.prototype.applyCrop = function (e) {
const annotation = annotationManager.getAnnotationsList().find(annotation => annotation.ToolName === "CropPage")
// get the positions of the crop that was added to extract information from
const cropRect = annotation.getRect();
documentViewer.getDocument().loadCanvasAsync({
pageNumber : annotation.PageNumber,
renderRect: cropRect,
drawComplete: async (canvas, index) => {
console.log('CROP_ABOUT_TO_BE_APPLIED')
// The 'canvas' would be the cropped area of the page.
// You can use 'toBlob' or 'toDataURl' extra the data from the canvas
}
});
applyCrop.apply(this, arguments);
};
});
is it possible to extract the text from cropped content(dataURL)?
Hello there.
Yes, you can do that. With the annotation coordinates, you can use the same strategy as of this post here: How to programmatically extract text within a given rectangle (x, y coordinates)?
Can you send the code again? It’s weirdly formatted and I don’t want to miss any details.
Also, can you send me that PDF so I can test on my end?
Hi, thanks for your support.
please check the below image and code.
useEffect(() => {
WebViewer({
path: “webviewer/lib/”,
initialDoc: “https://pdftron.s3.amazonaws.com/downloads/pl/webviewer-demo.pdf”,
fullAPI: true,
disableLogs: true
},
viewer.current,
).then(instance => {
instance.UI.disableElements([‘toolbarGroup-Shapes’]);
instance.UI.disableElements([‘toolbarGroup-View’]);
instance.UI.disableElements([‘toolbarGroup-Annotate’]);
instance.UI.disableElements([‘toolbarGroup-FillAndSign’]);
instance.UI.disableElements([‘toolbarGroup-Forms’]);
instance.UI.disableElements([‘toolbarGroup-Insert’]);
const { Annotations, documentViewer, annotationManager, Tools, PDFNet } = instance.Core;
instance.setToolMode('CropPage');
instance.disableElements(['redoButton', 'undoButton']);
var FitMode = instance.FitMode;
instance.setFitMode(FitMode.FitWidth);
const applyCrop = Tools.CropCreateTool.prototype.applyCrop;
Tools.CropCreateTool.prototype.applyCrop = async function (e) {
await PDFNet.initialize();
const annotation = annotationManager.getAnnotationsList().find(annotation => annotation.ToolName === "CropPage");
const cropRect = annotation.getRect();
documentViewer.getDocument().loadCanvasAsync({
pageNumber: annotation.PageNumber,
renderRect: cropRect,
drawComplete: async (canvas, index) => {
console.log('CROP_DATA', canvas.toDataURL());
}
});
const doc = await documentViewer.getDocument().getPDFDoc();
const extractPage = await doc.getPage(annotation.PageNumber);
const txt = await PDFNet.TextExtractor.create();
const pageRect = await PDFNet.Rect.init(cropRect.x1, cropRect.y1, cropRect.x2, cropRect.y2);
txt.begin(extractPage, pageRect, annotation.PageNumber); // Read the page.
const extractedText = await txt.getAsText();
console.log('text', extractedText);
applyCrop.apply(this, arguments);
};
}).catch((error) => {
console.log('error', error);
});
}, []);Hello there.
I was on a short vacation, thanks for your patience.
The code is still weirdly formatted. Can you send me a text file with the code?
Best regards
Hello there.
Here is a working code snippet for extracting the text based on a crop annotation rectangle on WebViewer 8.2:
WebViewer({
path: "/lib",
initialDoc: "https://pdftron.s3.amazonaws.com/downloads/pl/webviewer-demo.pdf",
fullAPI: true,
disableLogs: true,
useDownloader: false
}, document.getElementById('viewer')).then(async (instance) => {
instance.UI.disableElements(['toolbarGroup-Shapes']);
instance.UI.disableElements(['toolbarGroup-View']);
instance.UI.disableElements(['toolbarGroup-Annotate']);
instance.UI.disableElements(['toolbarGroup-FillAndSign']);
instance.UI.disableElements(['toolbarGroup-Forms']);
instance.UI.disableElements(['toolbarGroup-Insert']);
const { documentViewer, annotationManager, Tools, PDFNet } = instance.Core;
instance.setToolMode('CropPage');
instance.disableElements(['redoButton', 'undoButton']);
var FitMode = instance.FitMode;
instance.setFitMode(FitMode.FitWidth);
const extractText = (doc, pageNumber, top_x, top_y, bottom_x, bottom_y) => {
return new Promise(resolve => {
doc.loadPageText(pageNumber, text => {
doc.getTextPosition(pageNumber, 0, text.length, (arr) => {
var indexes = []
arr.filter((item, index) => {
if (item.x4 >= top_x && item.y4 >= top_y && item.x2 <= bottom_x && item.y2 <= bottom_y) {
indexes.push(index)
return true;
}
return false;
})
let str = '';
for (let i = 0, len = indexes.length; i < len; i++) {
str += text[indexes[i]];
}
resolve(str)
});
});
});
}
const applyCrop = Tools.CropCreateTool.prototype.applyCrop;
Tools.CropCreateTool.prototype.applyCrop = async function (e) {
const annotation = annotationManager.getAnnotationsList().find(annotation => annotation.ToolName === "CropPage");
const cropRect = annotation.getRect();
const doc = documentViewer.getDocument();
const pageNumber = annotation.getPageNumber();
const text = await extractText(doc, pageNumber, cropRect.x1, cropRect.y1, cropRect.x2, cropRect.y2);
console.log(text);
applyCrop.apply(this, arguments);
};
}).catch((error) => {
console.log('Catch Exception', error);
});
Hi, Felix thanks for your support.
is it possible to maintain pdf original structure after crop? what I’m trying is just to hide the crop popup and marks after apply (tick button) clicked, don’t want to edit the pdf page
please guide me on this.
Hello there.
Could you please elaborate more on what exactly you want to do? A few screenshots would be great as well.
hi, thanks Felix I figured it out
Hello Parthi.
That’s great to hear. Thanks for letting me know.
Hi @dfelix ,
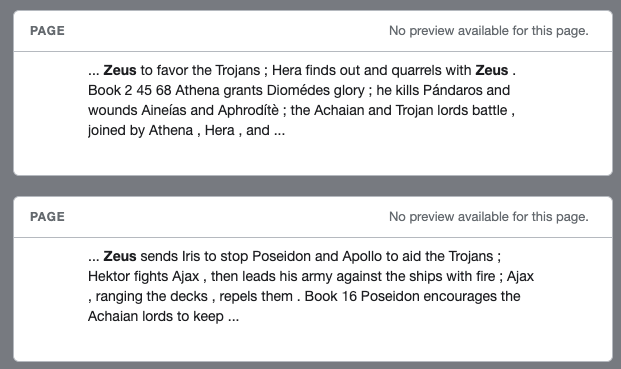
Is there a way to extract pre-defined regions of a page and display them as multiple snippets?
So instead of displaying a full page, I’d like to just display the important parts of the page. Users can click on a fullscreen button to view the whole page again.
Here is an example:
Any help will be appreciated ![]()