Preamble
While the PDFTron SDK does not natively support Dynamic XFA forms because it has been deprecated in the latest PDF specification, if your requirement is to programmatically flatten a large number of XFA forms to PDF, our Virtual Printer capabilities on Windows can help achieve this.
Prerequisites
-
Windows OS
In our experience, Adobe Reader is the only reliable software to handle the deprecated XFA format.
Steps
1. Acrobat Reader can print from the command line using the /t option like so:
AcroRd32.exe /t <filename> <printername> <drivername> <portname>
As such, ensure you can execute the following command on the Windows command line:
# Assumes default installation directory
C:\Program Files (x86)\Adobe\Acrobat Reader DC\Reader\AcroRd32.exe /t C:\path\to\xfa\document.pdf "PDFTron PDFNet"
By default, this will write a XPS file to:
C:\Users\%USERNAME%\AppData\Local\Temp\pdfnet.xps
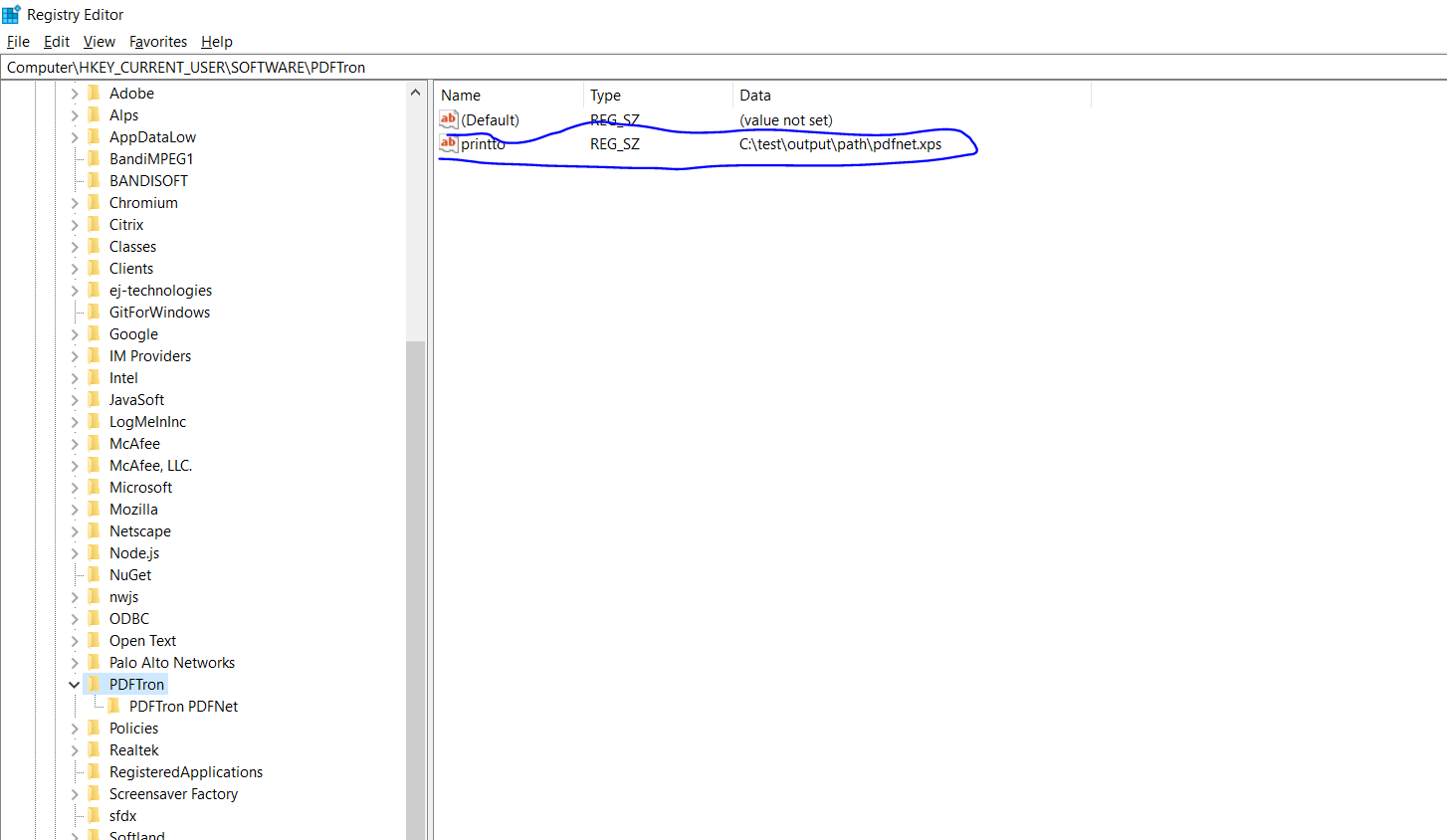
However, this can be adjusted by writing the following registry entry:
HKEY_CURRENT_USER\SOFTWARE\PDFTron\PDFTron PDFNet\printto
With a value like:
C:\my\output\path\pdfnet.xps
Note that you have to specify the file name at the end of the path.
Source: How to use the PDFTron PDFNet virtual printer directly?
2. Convert the resulting XPS file to PDF using the PDFTron SDK
3. For programmatic batch conversions:
a. Have your program invoke AcroRd32.exe in a similar manner to Step 1, waiting for the temporary XPS file to be written (i.e. use some sort of built in System IO method for your programming language to check for the file’s existence)
Note that you can watch the registry entries HKEY_CURRENT_USER\SOFTWARE\PDFTron\PDFTron PDFNet\jobid and HKEY_CURRENT_USER\SOFTWARE\PDFTron\PDFTron PDFNet\jobidComplete as means to detect for the print job starting and finishing, per How to use the PDFTron PDFNet virtual printer directly?
b. Convert the output XPS file using the PDFTron SDK as shown in Step 2
c. Delete the temporary XPS file
d. Repeat steps 3a to 3c for all XFA files
Here is a rough Java sample code to achieve this (please note the TODO for Production usage):
package pdftron;
import java.io.File;
import java.io.IOException;
import java.io.InputStream;
import java.nio.file.Files;
import java.nio.file.Paths;
import com.pdftron.common.PDFNetException;
import com.pdftron.pdf.Convert;
import com.pdftron.pdf.PDFDoc;
import com.pdftron.pdf.PDFNet;
import com.pdftron.sdf.SDFDoc;
public class XFAtoPDF {
public XFAtoPDF() {
super();
}
private static String checkForPdfnetXps(String pathToPdfnetXpsOutput) {
try {
InputStream is = Files.newInputStream(Paths.get(pathToPdfnetXpsOutput));
return org.apache.commons.codec.digest.DigestUtils.md5Hex(is);
} catch (IOException e) {
// File doesn't exist or the program cannot read it
return "";
}
}
public static void main(String[] args) throws PDFNetException, IOException, InterruptedException {
PDFNet.initialize("demo-key-goes-here");
String[] filesToConvert = {
// List of XFA Documents
};
final String tempXpsFile = "C:\\Users\\%USERNAME%\\AppData\\Local\\Temp\\pdfnet.xps";
for (String filename: filesToConvert) {
String oldPdfnetXpsHash = checkForPdfnetXps(tempXpsFile);
if (!oldPdfnetXpsHash.equals("")) {
final File tempXpsFileObj = new File(tempXpsFile);
if (tempXpsFileObj.exists()) {
if (!tempXpsFileObj.delete()) {
System.err.println("Could not delete " + tempXpsFile);
System.err.println("Ending the conversion process.");
System.exit(1);
}
}
}
ProcessBuilder builder = new ProcessBuilder(
"C:\\Program Files (x86)\\Adobe\\Acrobat Reader DC\\Reader\\AcroRd32.exe",
"/t",
"\"C:\\path\\to\\" + filename + "\"",
"\"PDFTron PDFNet\""
);
builder.redirectErrorStream(true);
builder.start();
String newPdfnetXpsHash = checkForPdfnetXps(tempXpsFile);
/**
* TODO Add a timeout on this, don't let it run indefinitely in-case the PDFNet Virtual Printer
* process didn't work
*/
while(oldPdfnetXpsHash.equals(newPdfnetXpsHash)) {
// Give the process some time to complete the print job
Thread.sleep(3000);
newPdfnetXpsHash = checkForPdfnetXps(tempXpsFile);
}
PDFDoc pdfDoc = new PDFDoc();
Convert.toPdf(pdfDoc, tempXpsFile);
pdfDoc.save("C:\\path\\to\\output" + filename, SDFDoc.SaveMode.LINEARIZED, null);
final File tempXpsFileObj = new File(tempXpsFile);
if (tempXpsFileObj.exists()) {
if (!tempXpsFileObj.delete()) {
System.err.println("Could not delete " + tempXpsFile);
System.err.println("Ending the conversion process.");
System.exit(1);
}
}
}
}
}