When I initially create the WebViewer, it works fine. But when I change the filePath to a different file, I get the following error:
Exception:
Message: PDF header not found. The file is not a valid PDF document.
Filename:
Function: Skipheader
Linenumber:
This happens even if I switch the filePath back to what the WebViewer was initially created with, when the file loaded without issue.
Additionally, this doesn’t happen when I am running both the React server and the API on my own machine under localhost. This only happens when we deploy them to a server, like our test server.
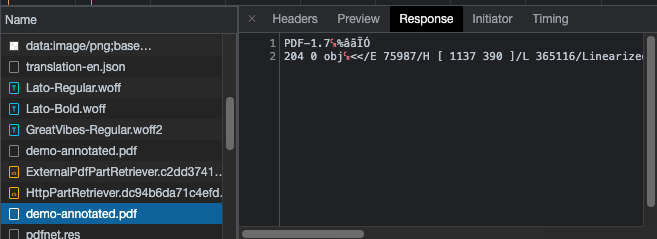
Thank you for contacting WebViewer’s support. This error normally shows up when WebViewer tries to open a file as a PDF but can’t (i.e. trying to open a .docx file as a PDF). Would it be possible to get a screenshot of your browser developer console network tab and what kind of response you are getting back from your server? Normally you should see something like the following
It’s possible you aren’t loading a PDF document or you are getting some unexpected data back from your server. It’s interesting that changing the value back to the initial value still give issues, it could be your browser is caching the data somewhere
I found the problem. The path I’m passing in starts with “./” so loadDocument() is inserting “lib/pdfTron/ui” (the path to the copy of the library I created) into the URL.